Hosting your own web site comes with a number headaches, not least sorting out backups so you can recover your data should disaster strike. A relatively painless solution for those of us with servers deployed on a cloud platform is to use snapshots.
To be honest it is a lot easier to use a third party hosting solution so they sort all this out for you but tech-fiddling enthusiasts, penny pinchers and gluttons for punishment will I hope enjoy this brief canter through the origins of snapshot technology and how it can be used as part of your backup strategy.
Virtual machines
One of the benefits of hosting your server on the public cloud is that the big cloud providers all offer a multitude of tools and services to make your life as an administrator easier.
For those of us that remember the arseache involved in purchasing and commissioning hardware, the fact that it is now possible to deploy a virtual server with a few keystrokes and a credit card is little short of miraculous. Our debt of gratitude for these very modern conveniences are owed in large part to the engineers at IBM who invented virtual machines in the 1960s.
The operating systems that ran the IBM computers of the era were single-tasking, meaning that only one process could execute at a time and, in an attempt to maximise utilisation of their (very expensive) hardware, IBM invented a solution that allowed a single physical server to run multiple operating systems - which IBM called virtual machines - concurrently[1].
This allowed several people to use the machine at the same time and - although the underlying hardware was still only able to run a single task at a time - it appeared to the end user that they had sole use of the machine.


IBM System/370 Model 145 (1970), one of the first machines to run the VM/370 Virtual Machine Facility (the system is still supported today) / an IBM 3270 data entry terminal, ©️ Jonathan Schilling
{kind=link}
Eventually multi-user operating systems like UNIX[2], which could share access to memory and other system resources between users, came to dominate the server market but, because it was still convenient to run multiple independent operating systems on the same hardware, virtualisation technology continued to be developed in parallel[3].
Utility Computing
Amazon are one of the few companies in the world that routinely build their own power substations[4] but a century ago everyone was at it. The Edison Illuminating Company opened the world's first power stations generating electricity for public use in the early 1880s, but it took decades for reliable national electricity distribution networks to be established and, until then, you were on your own. Steel mills, coal mines, shipyards, textile mills, railways and even large private estates had little choice but to build their own power stations.



The Edison Electric Light Station at Holborn Viaduct (London, 1880), Jack Harris / Edison's Pearl Street Station, New York (1882) Earl Morter / The Bristol Tramways & Carriage Company’s Power Station, photo from British Listed Buildings
{kind=link}
At the dawn of the information super highway companies had no option other than to host their websites on their own hardware, a costly exercise that left them on the hook for capacity planning, hardware repairs, software upgrades and ensuring the infrastructure was secure from natural disasters, malicious attacks, neglect and human error.
As with the centralisation of power generation, a similar revolution occurred in the world of technology and, just as building your own power station - although once commonplace - would be daft under nearly every conceivable circumstance today, no one in their right mind builds their own data centres any more.
Amazon Web Services
In the 90s lots of hosting companies offered to rent out some data storage or, if you were feeling flush, entire servers most of which were specified for peak loads that were rarely, if ever, reached. As a result rented hardware was generally under-utilised and therefore expensive. A number of these hosting companies started to offer virtualized solutions which allowed them to run multi-tenanted servers, reducing their costs and allowing them to provide a more competitive service.
The real revolution in hosting begin in 2004 when Amazon, who were at the time a struggling online bookseller, started to experiment with making aspects of their own infrastructure available to other businesses. The initial experimental services focused on providing access to Amazon's product catalogue and ordering system. They called the new product Amazon Web Services:

By the time of the general release of their new service in 2006 they had settled on the idea of offering access to computing power, storage, and databases on a pay-as you go basis. They called the new features EC2 (Elastic Compute Cloud):
This was a decision that within a few years would change the face of the hardware technology industry and cause huge disruption to technology giants like IBM, Oracle and HP.

Inside an Amazon data centre. Amazon now have hundreds of data centres all over the world
Block storage and snapshots
AWS was an extraordinary success and Amazon is now the largest server infrastructure provider in the world - and one of the biggest companies in existence - running the infrastructure for hundreds of thousands of businesses.
In the early days of AWS, even Amazon was unsure about how to solve some of the challenges business would encounter running virtualised infrastructure:
An instance can have a copy of MySQL installed and can store as much data as it would like ... but there’s no way to ensure that the data is backed up in case the instance terminates without warning.What if the slave (client) wasn’t another instance of MySQL? What if it was a very simple application which pulled down the transaction logs and wrote them into Amazon S3 objects on a frequent and regular basis? If the master were to disappear without warning (I could say crash here, but I won’t), the information needed to restore the database to an earlier state would be safely squirreled away in S3. Jeff Barr 2006
Around 18 months later they settled on a solution and introduced a persistent storage layer for EC2, called the Elastic Block Storage service
As the name suggests the service offered block-level storage: each volume[5] of data is divided up into blocks and stored as separate pieces, each with a unique identifier. This type of storage decouples the data from the end user environments, allowing data to be spread across multiple remote network attached storage devices. When a user or application requests data the storage system retrieves the data from the network, reassembles the data blocks and presents the data to the user or application.
"Snapshotting" is the process of copying these blocks so that the data can be replicated in a new location. When the first snapshot of a volume is taken all the blocks that have ever been written to a volume are copied and the location of each block is saved, creating an index that lists the location of all the blocks belonging to the snapshot.
When a second snapshot is taken of the same volume only the blocks that have changed since the first snapshot are copied and a new index is added to the second snapshot. Some of the blocks are shared with the first snapshot, and some are new.
If you revert to one of your snapshots, every block of data that was added or changed since the snapshot was taken will be replaced from the location listed in the snapshot.
Snapshots need to be consistent, that is they must reflect the state of the volume at the point the snapshot is started. What happens if data is still being written to the volume as the snapshot is being created? The storage system can detect write operations on blocks yet to be copied and will then pause the write operation before copying that block out to the snapshot. Once the block is copied, the write operation resumes along with the rest of copy process.
Lightsail snapshots
A lightsail snapshot takes an image of all the storage used by your Lightsail instance, creating a copy of your system configuration and data at a certain point in time. Since snapshots are incremental - only saving blocks that have changed - the amount of storage required when multiple snapshots are retained is minimised.
Having access to point-in-time backups like this is very useful: you can use snapshots to recover the data saved at the time the snapshot was taken, or you can use them as a restoration point before performing major upgrades to the system. You can also use them to start up replicas of your server for testing purposes.
You can manually take snapshots of your Lightsail instances whenever you like:
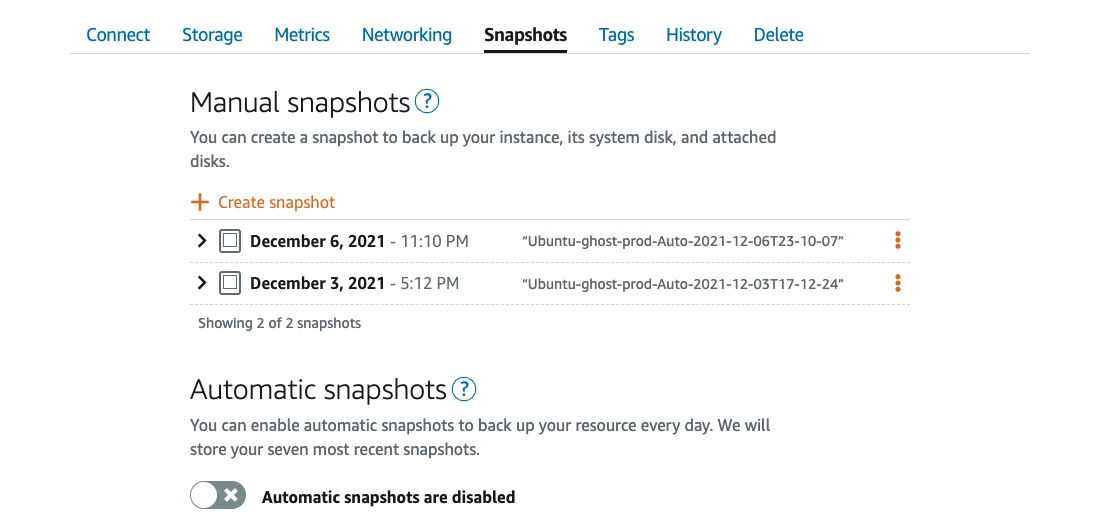
Or you can enable the automatic snapshots feature so that Lightsail will take a daily snapshot for you and retain the seven most recent copies.
AWS does not charge for creating a snapshot but does charge for storing the snapshot data (at the time of writing the charge is $0.05 per GB per month). As mentioned above, Lightsail organises snapshot storage so that for each consecutive snapshot, you are only charged for the data that’s changed from the previous one.
Despite the inflexibility - you are restricted to 7 daily snapshots - automated snapshots are very convenient.
If you can't live with the limitations of the 7 daily snapshot system and would like to automate the snapshots yourself, perhaps using a different backup schedule, then this is possible using a relatively straightforward shell script.
Automating snapshots
A word of caution, I do this kind of thing for my own amusement and the script below comes without any kind of warranty or support. You can run it from the command line on your server, for instance before a major update, or set it up to run as a regular scheduled job choosing a schedule of your own choosing and retaining as many snapshots as you desire:
 nickabs
nickabsAs explained in the README there are some pre-requisites to get it to work:
create an AWS account to manage your snapshots
You will need to use the the IAM facilities in the AWS admin console to create a new user to manage the snapshots[6]. You will also need to create a new policy with the necessary permissions for managing snapshots. This script can also send confirmation & error emails via the SES email facility on AWS, so you may also want to allow that too. The profile permissions I use are shown below:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1613657436000",
"Effect": "Allow",
"Action": [
"ses:SendEmail"
],
"Resource": [
"*"
]
},
{
"Sid": "Stmt1613657458000",
"Effect": "Allow",
"Action": [
"lightsail:CreateInstanceSnapshot",
"lightsail:DeleteInstanceSnapshot",
"lightsail:GetInstanceSnapshots"
],
"Resource": [
"*"
]
}
]
}
Finally you need to attach your policy to a new group and add your new user to it.
The user I created is called LightsailSnapshotAdmin, the group is LightsailSnapshotAdmins and the policy name is LightsailSnapshotAccess, but you can choose whatever names you please.
Install AWS command line interface
The script uses the aws command line interface to manage the Lightsail snapshots.
Once you have installed the aws command line application you will need to install a named profile for your snapshot admin account onto the virtual machine where the script is installed. This profile will be used as a parameter for the script so it can authenticate with AWS.
The profile contains the access key for your AWS snapshot user account and, although the account will have limited permissions (see above), the key should still be kept secret and you should make sure you understand the security implications of storing access keys.
set up email notifications
If you want to use the email notification option in the script then you need to configure AWS SES mail. As noted above your AWS snapshot admin user will need ses:SendEmail permission.
Instructions on how run the script and to schedule a regular backup job are in the github readme.
Limitations
You can test the restoration of a snapshot by using the 'create new instance' feature. This will create a new instance that will exactly replicate the state of your instance at the time the snapshot was taken.
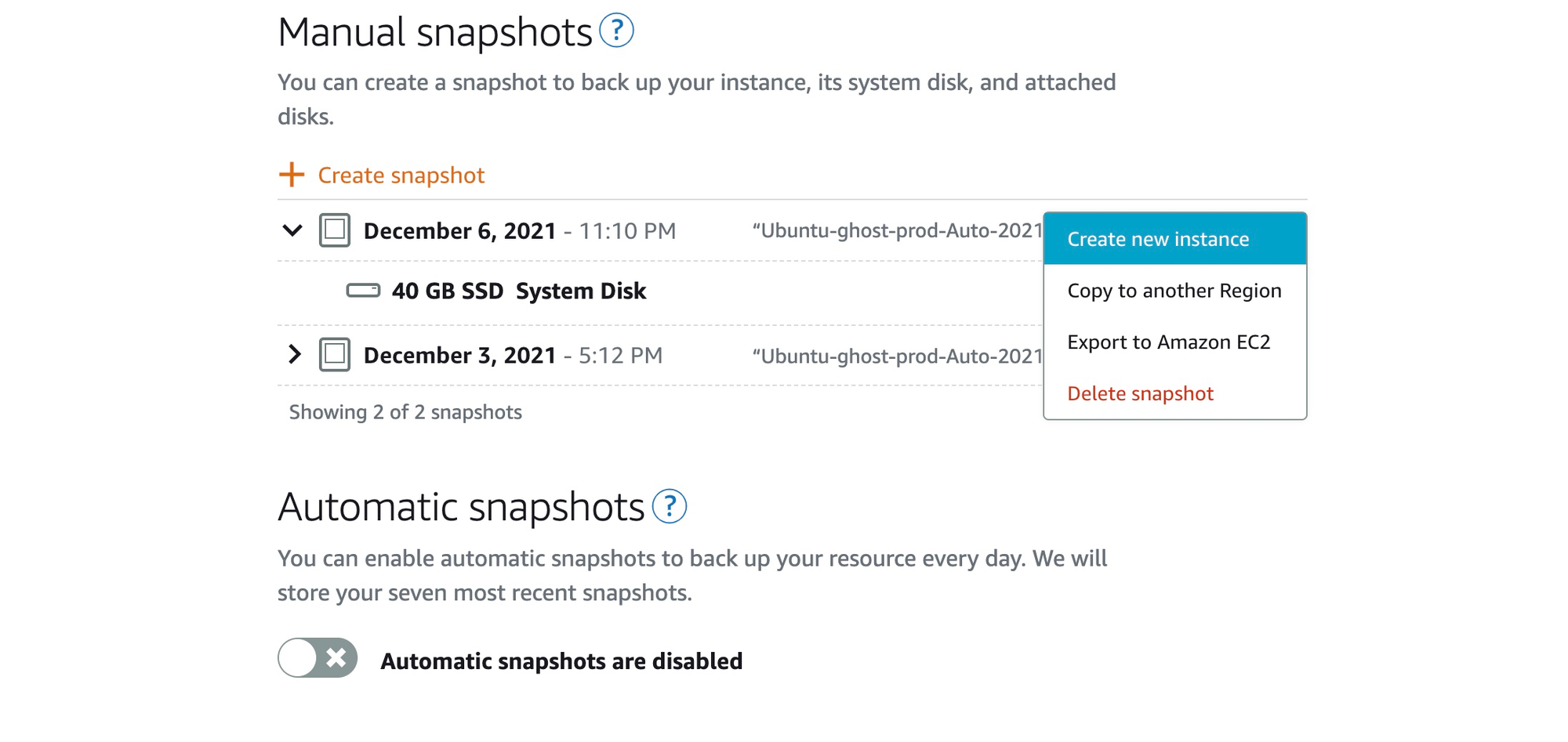
When the restored instance is restarted the website will probably work correctly, however, snapshots only capture data that has been written to your Amazon EBS volume at the time the snapshot command is issued. If the snapshot is run when data is still in memory, say because the database is midway through processing a transaction or because operating system memory buffers are being flushed to disk, then the data in memory is discarded. Technically the snapshot is said to be crash-consistent, similar to unplugging a computer while it is running and then turning it back on.
Modern databases and filesystems are designed with a level of resilience to this type of data inconsistency and will generally be able to recover to a consistent state after a restoration, but there is no guarantee that data won't be lost. If you are running a commercial web site or storing very valuable data then this is a risk you will need to worry about but for the rest of us the risk may well be acceptable.
Conclusion
If you can be bothered to do all the above then you will now be able to initiate snapshots from the command line almost as easily as if you had just clicked the 'automatic snapshot' button inside the Lightsail admin web site! Congrats!
Alternative backup strategies
What if you are too mean to pay Amazon to store your snapshots? Or you want to recover a single file rather than the whole system? Or you want to store your backups outside of AWS? Read on in the next thrilling instalment.
References
| 1⏎ | The original CP/CMS system was released commercially as the VM/370 operating system, and lives on today in the z-series mainframe operating systems | 2⏎ | DARPA awarded MIT with $2 million for Project MAC (Multiple Access Computing) in 1963. The funding included a requirement to develop technology allowing for a “computer to be used by two or more people, simultaneously". The first operating system supporting time-sharing of this type was Multics, the predecessor of the Unix family. |
| 3⏎ | The desire to maximise use of available hardware that caused IBM to invent VMs has driven a great deal of the innovation in the cloud, including the relatively recent support for container and serverless technologies, both of which allow the machine resources to be allocated at a more granular level, thus allowing more effective use of the hardware. But this is a tale for another time... |
| 4⏎ | In a weird throwback, the hyper cloud vendors Amazon, Google and Microsoft, do sometimes build their own power stations in order to avoid disrupting the local supply with the huge electricity demands of their data centres. |
| 5⏎ | In the case of a standard lightsail instance there is a single volume for the system disk. Incidentally, block storage, was also invented by IBM too (1962). |
| 6⏎ | While you are in the IAM tool you migth want to set up a separate Lightsail Admin user so you don't have to keep logging in with your root email user admin account. I use a separate admin account that is associated with the standard AWS lightsail policy but can't use any of the other AWS features, such as billing user, administration etc. |